Direction vectors of
the LSDs on a single neuron from the fly visual system. Colors correspond
to the direction in which the neuronal processes travel.
We present a simple, yet effective, auxiliary learning task for the problem of
neuron segmentation in electron microscopy volumes. The auxiliary task
consists of the prediction of Local Shape Descriptors (LSDs), which we combine
with conventional voxel-wise direct neighbor affinities for neuron boundary
detection. The shape descriptors are designed to capture local statistics
about the neuron to be segmented, such as diameter, elongation, and direction.
On a large study comparing several existing methods across various specimen,
imaging techniques, and resolutions, we find that auxiliary learning of LSDs
consistently increases segmentation accuracy of affinity-based methods over a
range of metrics. Furthermore, the addition of LSDs promotes affinity-based
segmentation methods to be on par with the current state of the art for neuron
segmentation (Flood-Filling Networks, FFN), while being two orders of
magnitudes more efficient - a critical requirement for the processing of
future petabyte-sized datasets. Implementations of the new auxiliary learning
task, network architectures, training, prediction, and evaluation code, as
well as the datasets used in this study are publicly available as a benchmark
for future method contributions.
Connectomics is a relatively new field combining neuroscience, microscopy, biology and computer science.
The goal is to generate maps of the brain at synaptic resolution. By doing so,
it will hopefully lead to a better understanding of how things work and
subsequently advance medical approaches to various diseases.
The datasets required to produce these brain maps are massive since they have
to be imaged at such a high resolution.
Manually reconstructing wiring diagrams in the datasets is extremely time consuming and
expensive so there is a great need to automate the process.
Reconstructing neurons is challenging because many consecutively correct decisions must be made. Errors can propagate throughout a dataset easily.
Methods need to also be computationally efficient and scalable to account
for the size of the data.
We present a novel approach to neuron segmentation, Local Shape Descriptors
(LSDs) - a 10-Dimensional embedding used as an auxiliary learning objective
for boundary detection.
We find that the LSDs help improve boundaries and subsequent neuron
reconstructions in several large and diverse datasets and are competitive with
the current state of the art, albeit two orders of magnitude faster.
Background
Connectomics
Connectomics is an emerging field which integrates multiple domains including
neuroscience, microscopy, and computer science. The overarching goal is to
provide insights about the brain at resolutions which are not achievable with
other approaches. The ability to study neural structures at this scale will
hopefully lead to a better understanding of brain disorders, and subsequently
advance medical approaches towards finding treatments & cures.
The basic idea is to produce "connectomes" which are essentially maps of the
brain. These maps, or "wiring diagrams", give scientists the ability to see how
every neuron interacts through synaptic connections. They can be used to
complement existing techniques and
drive future experiments .
Currently, only Electron Microscopy (EM) allows imaging of neural tissue at a
resolution sufficient to see individual synapses. Unfortunately, by imaging
brains at such high resolution, the resulting data is massive. Let's consider a
fruit fly example. A full adult fruit fly brain (FAFB) imaged with ssTEM
at a pixel resolution of ~4
nanometers and ~40 nanometer thick sections, comprises ~50 teravoxels of data
(neuropil). For reference, a
voxel is a volumetric pixel, and the "tera" prefix means 1012. So,
one fly brain contains upwards of 50,000,000,000,000 volumetric pixels. To put
that in perspective, Abbott et al.
argue that, assuming a scale where 1000 cubic microns is equivalent to 1
centimeter, a fruit fly brain would comprise the length of 6 and a half Boeing
747 aeroplanes. This still pales in comparison to a mouse brain which would
require the acquisition of 1 million terabytes of data.
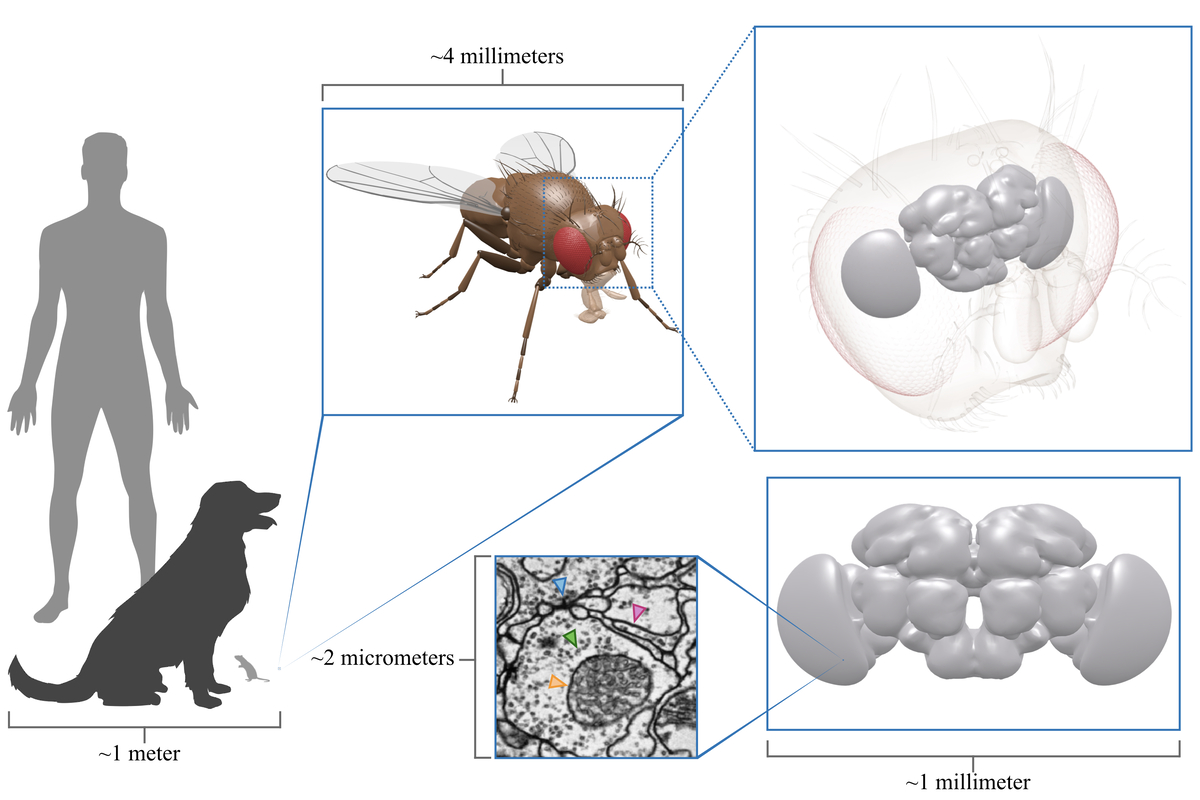
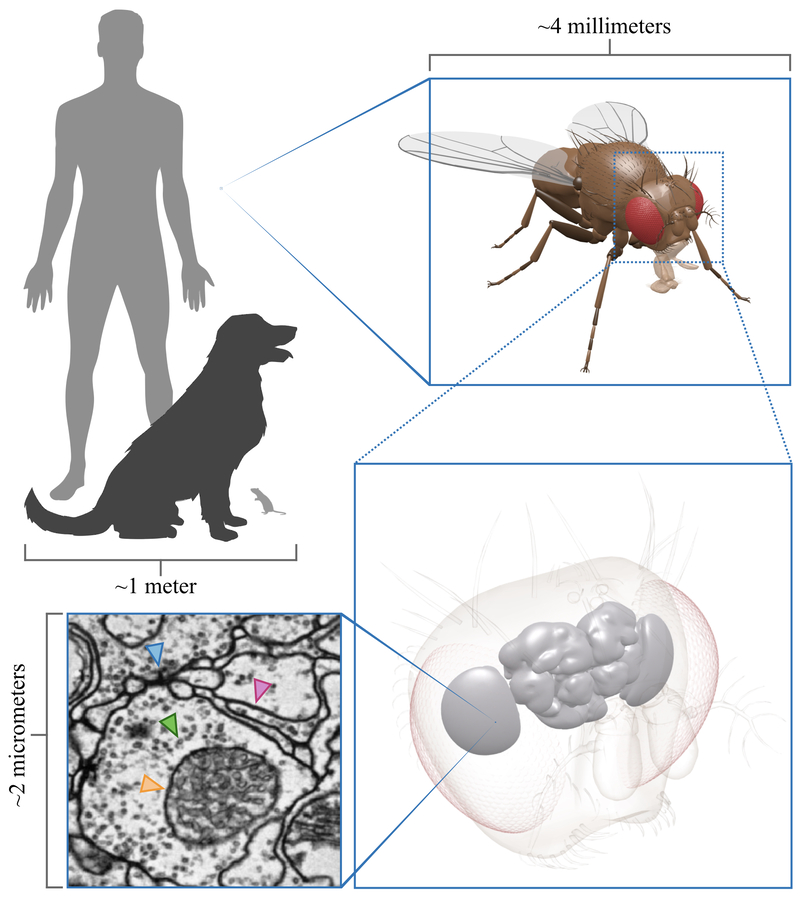
Scale perspective. A
fruit fly brain imaged at synaptic resolution takes up 100's of terabytes of
storage space. It allows us to see fine structures such as neural plasma
membranes (pink arrow), synapses (blue arrow), vesicles (green arrow) and
mitochondria (orange arrow). 3D fruit fly model kindly provided by Igor Siwanowicz